
























 分享文章
分享文章

LaWGPT基于中文法律知识的大语言模型
智能
2023-05-31 02:41
声明:该文章由作者(唐钰)发表,转载此文章须经作者同意并请附上出处(0XUCN)及本页链接。。
LaWGPT 是一系列基于中文法律知识的开源大语言模型。
该系列模型在通用中文基座模型(如 Chinese-LLaMA、ChatGLM 等)的基础上扩充法律领域专有词表、大规模中文法律语料预训练,增强了大模型在法律领域的基础语义理解能力。在此基础上,构造法律领域对话问答数据集、中国司法考试数据集进行指令精调,提升了模型对法律内容的理解和执行能力。
详细内容请参考技术报告。
项目结构
LaWGPT
├── assets # 项目静态资源
├── data # 语料及精调数据
├── tools # 数据清洗等工具
├── README.md
├── requirements.txt
└── src # 源码
├── finetune.py
├── generate.py
├── models # 基座模型及 Lora 权重
│ ├── base_models
│ └── lora_weights
├── outputs
├── scripts # 脚本文件
│ ├── finetune.sh # 指令微调
│ └── generate.sh # 服务创建
├── templates
└── utils
数据构建
本项目基于中文裁判文书网公开法律文书数据、司法考试数据等数据集展开,详情参考中文法律数据汇总
初级数据生成:根据 Stanford_alpaca 和 self-instruct 方式生成对话问答数据
知识引导的数据生成:通过 Knowledge-based Self-Instruct 方式基于中文法律结构化知识生成数据。
引入 ChatGPT 清洗数据,辅助构造高质量数据集。
模型训练
LawGPT 系列模型的训练过程分为两个阶段:
第一阶段:扩充法律领域词表,在大规模法律文书及法典数据上预训练 Chinese-LLaMA
第二阶段:构造法律领域对话问答数据集,在预训练模型基础上指令精调
二次训练流程
参考 src/data/example_instruction_train.json 构造二次训练数据集
运行 src/scripts/train_lora.sh
指令精调步骤
参考 src/data/example_instruction_tune.json 构造指令微调数据集
运行 src/scripts/finetune.sh
计算资源
8 张 Tesla V100-SXM2-32GB
模型评估
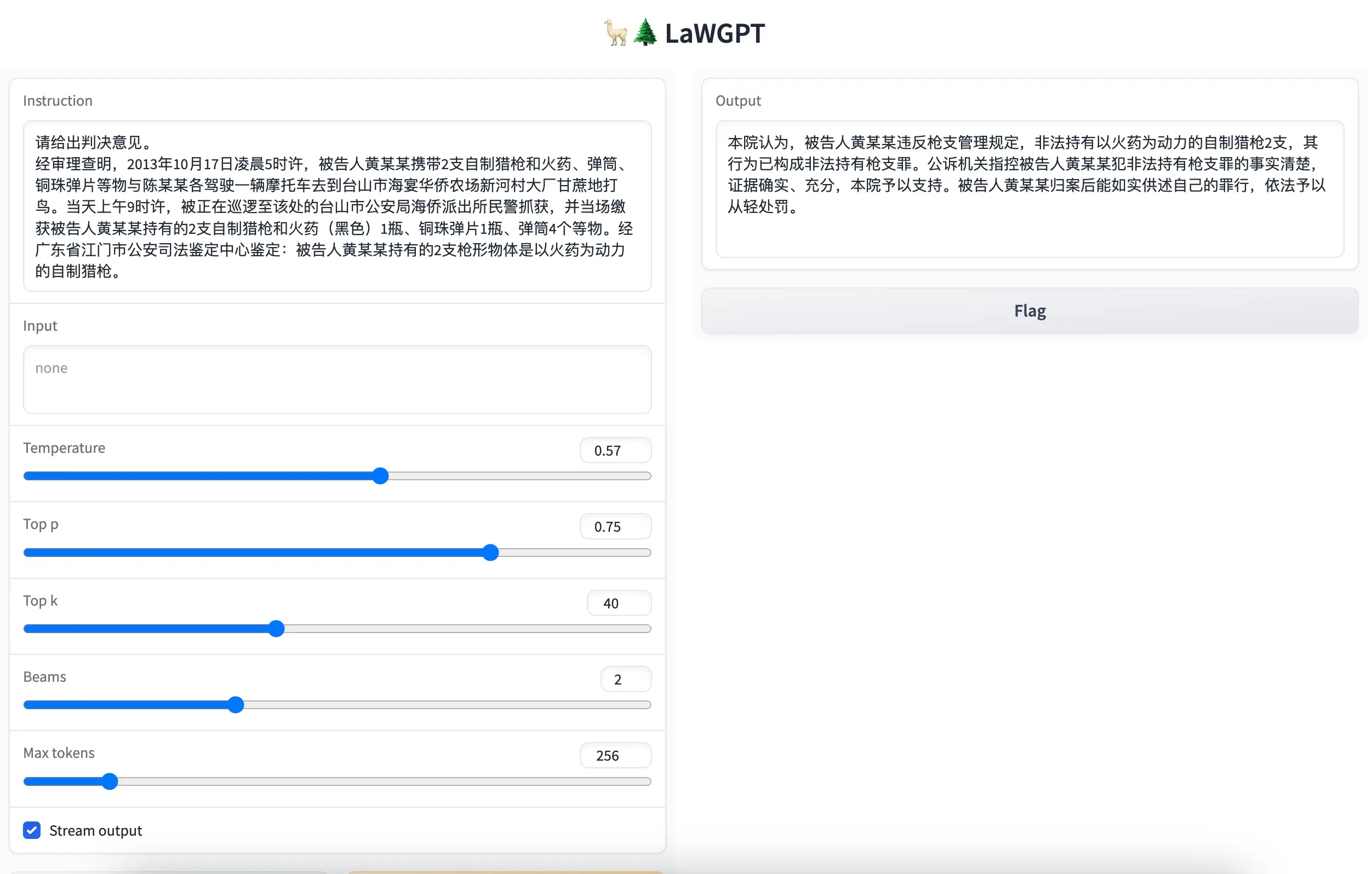
输出示例
问题:请给出判决意见。
问题:请介绍赌博罪的定义。

问题:请问加班工资怎么算?

局限性
由于计算资源、数据规模等因素限制,当前阶段 LawGPT 存在诸多局限性:
数据资源有限、模型容量较小,导致其相对较弱的模型记忆和语言能力。因此,在面对事实性知识任务时,可能会生成不正确的结果。
该系列模型只进行了初步的人类意图对齐。因此,可能产生不可预测的有害内容以及不符合人类偏好和价值观的内容。
自我认知能力存在问题,中文理解能力有待增强。

[超站]友情链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
关注数据与安全,洞悉企业级服务市场:https://www.ijiandao.com/
排名
热点
搜索指数
- 1 跟着总书记一起厚植文化底蕴 7904218
- 2 全世界都知道中国人放假了 7809298
- 3 央视秋晚7大神级现场 7712728
- 4 60秒延时摄影赏中秋月 7618844
- 5 游客投喂胡萝卜 羊驼:真吃不动了 7521482
- 6 谢娜首次主持央视秋晚 7426816
- 7 男子假期带3岁孙子推100岁爷爷遛弯 7329927
- 8 诺贝尔奖奖金124年没花完 7238449
- 9 孙子误吃过期月饼 奶奶掏出过期药 7140219
- 10 2025年诺贝尔生理学或医学奖揭晓 7047854

