
























 分享文章
分享文章

基于python爬虫模拟登陆豆瓣#爬虫教程#
安全
2018-12-14 00:18
声明:该文章由作者(ksbugs)发表,转载此文章须经作者同意并请附上出处(0XUCN)及本页链接。。
一、简介
工具:Google chrome
python 爬虫登陆方式一般有两种:
第一种:使用post登陆,即需要输入账号密码等选项,
第二种:使用cookies登陆,即把已登陆好账号的cookies拷贝到代码中,
两种方式各有优缺,第一种可能再代码运行中会出现验证码选项,需要写验证码方面的代码,
第二种较为方便。
二、获取需要的数据
我们以豆瓣电影《战狼2》为例,详细介绍如何获取这些数据
电影地址:
https://movie.douban.com/subject/26363254/
我们要爬取的是短评,打开短评页:
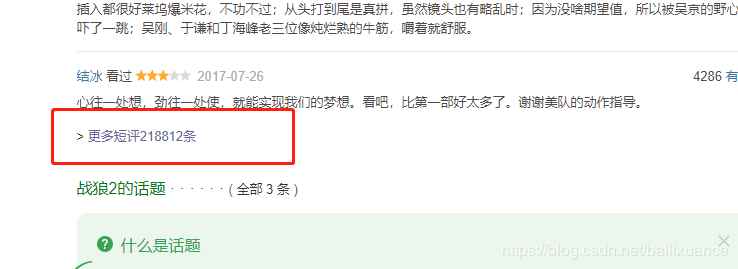
地址:
https://movie.douban.com/subject/26363254/comments?sort=new_score&status=P
1、打开开发者模式:
按F12键,或者页面右键点击”检查“,或者设置--开发者模式,三种方法都可以
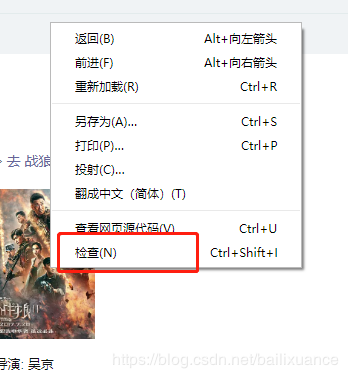
打开后如图:

2、在左侧登陆豆瓣账号,右侧分别点击 Network ,ALL, Name下面的login,如下图:
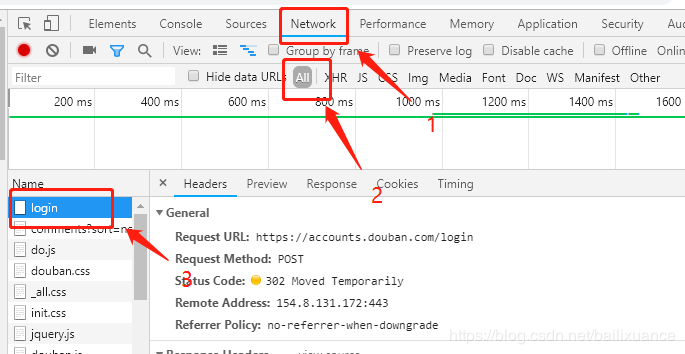
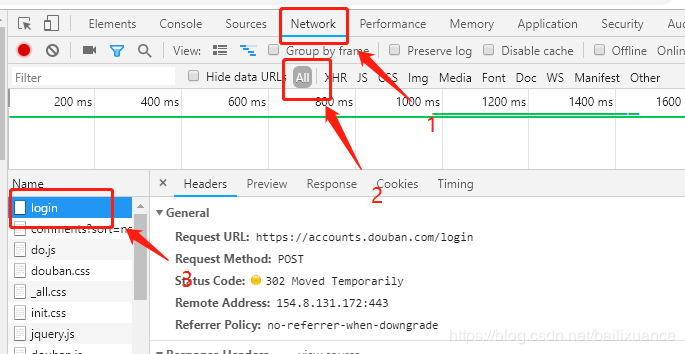
获取post数据:
在login的Headers下面,Form Data下面就是post登陆需要的数据
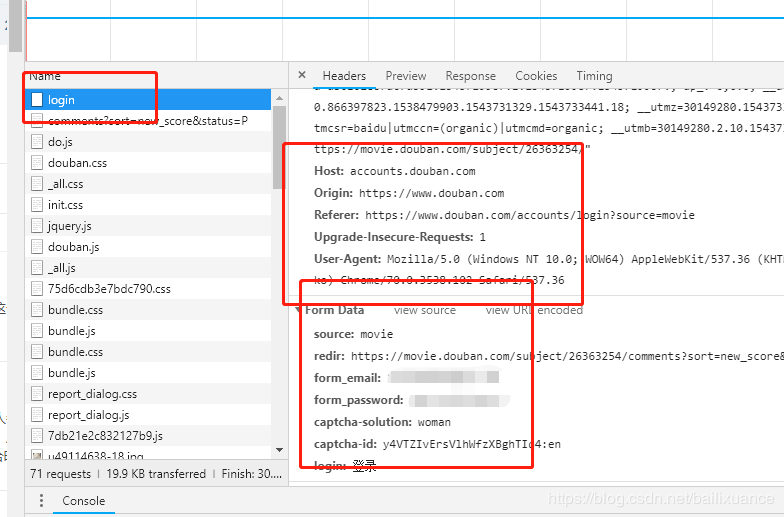
获取cookie数据:
在Name下面找到comments?sort=new_score&status=P(网址的后半截),右边的headers找到cookie,
即我们要的cookie数据,直接复制下来

同时,login也有cookie,但是不知道这两者的区别是什么,

参考:
https://blog.csdn.net/c091728/article/details/78347915
---------------------
作者:bailixuance
来源:CSDN
原文:https://blog.csdn.net/bailixuance/article/details/84715924
版权声明:本文为博主原创文章,转载请附上博文链接!

[超站]友情链接:
四季很好,只要有你,文娱排行榜:https://www.yaopaiming.com/
关注数据与安全,洞悉企业级服务市场:https://www.ijiandao.com/
排名
热点
搜索指数
- 1 总书记的这六天 7904467
- 2 为什么微信上那么多人住在安道尔 7808433
- 3 中国最重要的五大城市群 定了 7714394
- 4 育儿补贴申领正式全面开放 7616666
- 5 女飞行员:若有人敢来挑衅 那就试试 7523854
- 6 山姆们卖爆了 代工厂们赚麻了 7427033
- 7 博主“农村细妹”突发脑溢血去世 7331157
- 8 人民日报谈“禁带电话手表到学校” 7238361
- 9 女子高铁上脱鞋 举起双脚做拉伸 7135463
- 10 吉大两名新生同名同日生来自同省份 7044807

