


















 分享文章
分享文章
新闻分类
-

奶奶怀疑孙女遭男子性侵,将对方砍伤获刑 男子因涉嫌强奸罪、猥亵儿童罪被立案侦查
孔某因怀疑自己的孙女遭到男子王某性侵,用菜刀将对方砍伤。而男子在被砍伤约两个月后,警方也以涉嫌强奸罪、猥亵儿
 寂寞撒谎
2025-08-19
寂寞撒谎
2025-08-19
-

《长安的荔枝》发布全新预告及海报 大鹏白客齐聚
电影《长安的荔枝》发布一支求胜“荔”版预告,唐代小吏李善德一朝喜任“荔枝使”,还没高兴多久竟发现自己被人“做
 范范66668888
2025-06-16
范范66668888
2025-06-16
-

《向阳·花》曝预告 赵丽颖为角色在剧组手语交流
日前,由冯小刚执导,赵丽颖领衔主演,兰西雅特别介绍出演,啜妮、王菊、程潇主演的电影《向阳·花》发布“豁出去”
 lingxi
2025-03-08
lingxi
2025-03-08
-
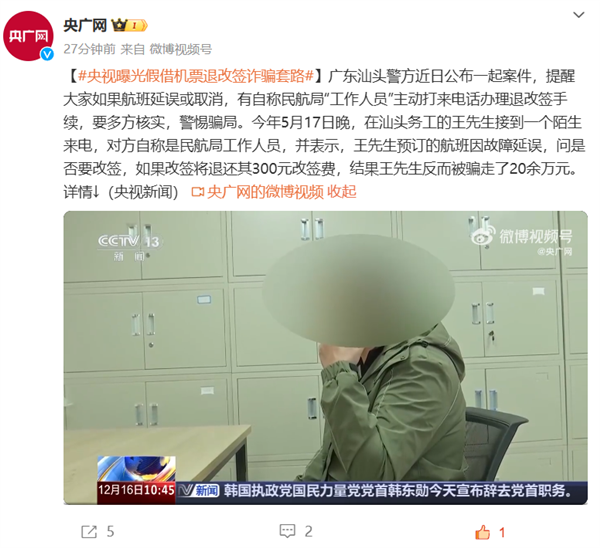
央视曝光假借机票退改签诈骗套路:说退300元结果被骗20万
据央视新闻报道,广东汕头警方近日公布一起案件,提醒大家如果航班延误或取消,有自称民航局“工作人员”主动打来电
 hades
2024-12-16
hades
2024-12-16
-

刘亦菲激罕晒透视泳装!卧躺沙滩尽现火辣蜜桃翘臀
37岁顶流女星刘亦菲自出道后演出不少剧集,凭借清新脱俗的气质让她获得了“神仙姐姐”的封号,近日又因在热播剧集
 第324号房间
2024-11-05
第324号房间
2024-11-05
-

《变形金刚:起源》获超高影评分
正在部分影院点映的《变形金刚:起源》获得多数影评人士好评,其烂番茄指数高达91/100:《新闻日报》评论说,
 林嫣
2024-09-17
林嫣
2024-09-17
-

辽宁男子疑杀害妻女及丈母娘后潜逃
顶端新闻记者 杨晓妍7月11日,辽宁省海城市公安局发布的一则悬赏通告引发网友关注,犯罪嫌疑男子李某胜涉及一起
 乌索普
2023-07-13
乌索普
2023-07-13
-

长沙playhouse解放西浩斯酒吧低消
长沙解放西路PLAY HOUSE酒吧中文名浩斯酒吧,位于天心区黄心南路445号,座位全场129张座位 V卡
 乌启豪
2023-06-07
乌启豪
2023-06-07
-

男子杀妻案开庭:妻子曾帮其还债
案发一年后,上海男子高某杀妻案于4月12日在上海市第一中级人民法院一审开庭。受害者婷婷的家属向红星新闻记者表
 云梦泽
2023-04-14
云梦泽
2023-04-14
-

特斯拉起诉前员工窃密 涉及新型超级计算机
北京时间8月19日消息,特斯拉发起一项诉讼,声称一名其前热力工程师非法转移了公司新超级计算机的机密技术信息,
 稍尽春风犹如候鸟
2022-08-19
稍尽春风犹如候鸟
2022-08-19
-
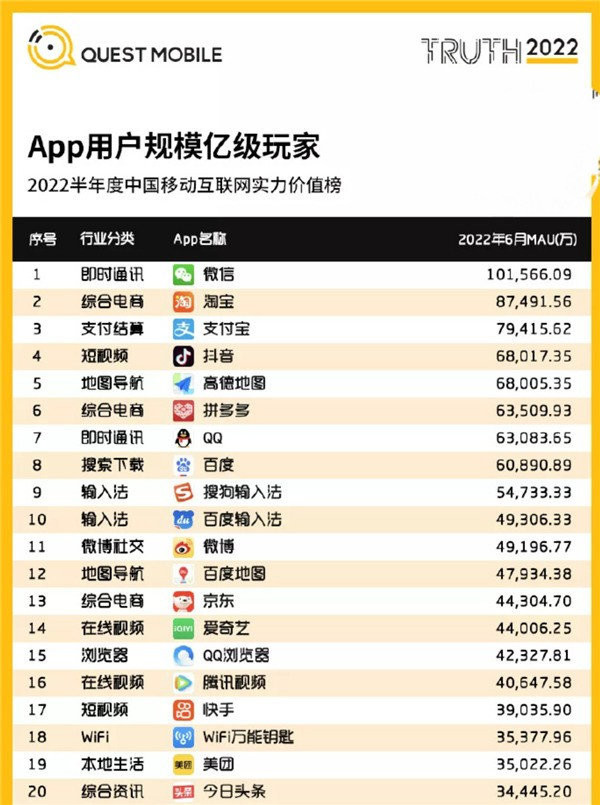
国内用户数量最多的20款App排名 看看你手机里有几款
手机中国注意到,有调研机构公布了国内用户数量最多的20款App排名。榜单信息显示,这些App的月度活跃用户数
 殇情
2022-08-03
殇情
2022-08-03
-

TikTok将美国用户数据转移至甲骨文Oracle本土服务器
据路透社,TikTok 已成功将其美国用户的数据信息迁移到甲骨文公司 (Oracle)的服务器上,从而解决美
 吟吟娘
2022-06-18
吟吟娘
2022-06-18
-
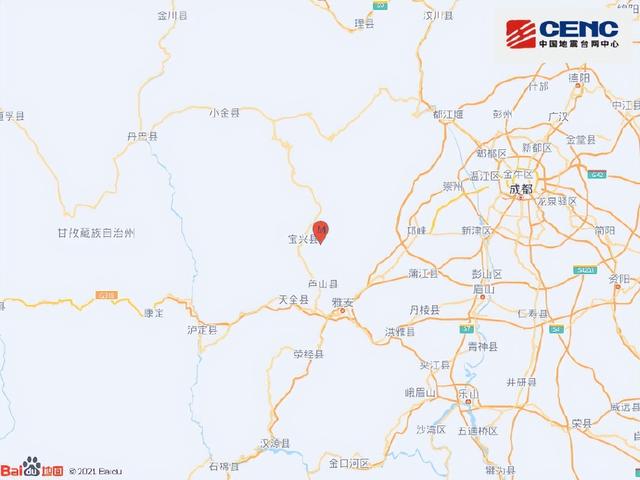
雅安5分钟连发两次地震
6月1日,据中国地震台网速报:06月01日17时03分在四川雅安市宝兴县(北纬30.37度,东经102.92
 雪碧模特
2022-06-01
雪碧模特
2022-06-01
-
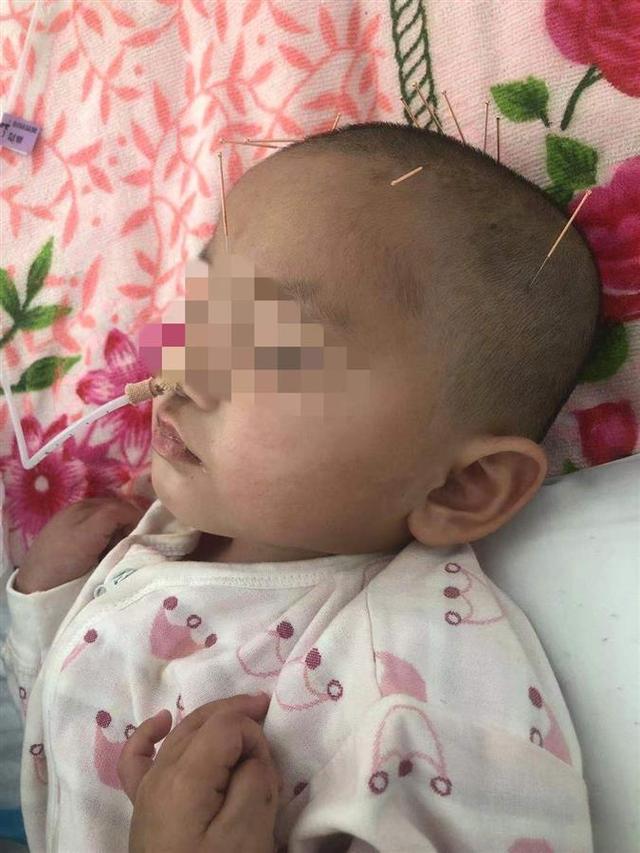
2岁女童参加喜宴后毒鼠强中毒
1月7日,山东聊城2岁女童小满(化名)仍在医院接受治疗。1个月前,小满与大伯一同参加了村里的婚宴。没想到回家
 外星人陈山
2022-01-08
外星人陈山
2022-01-08
-

针对“阿里女员工称被侵害”案,济南市公安局已成立工作专班
“阿里女员工称被灌酒猥亵”一事引发关注。8月10日下午,澎湃新闻从济南市公安局获悉,针对网上引发关注的“阿里
 廖miko
2021-08-10
廖miko
2021-08-10
-
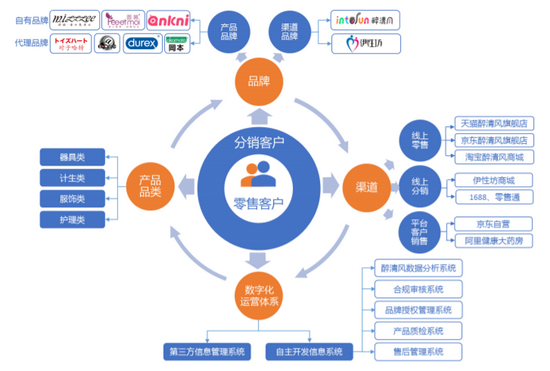
“情趣用品第一股”醉清风折戟创业板 三年刷单4600万
递交招股书不到一个月的“情趣用品第一股”醉清风IPO审核被终止。2021年7月22日,深交所发布《关于终止对
 qubegirl
2021-07-26
qubegirl
2021-07-26
-

小米“618”战报:全平台支付金额破190亿,同比增长90%
6月19日消息,今日,小米公司在微博发布“618”战报,6月1日-18日,全平台支付金额破190亿,同比增
 孙云玲
2021-06-19
孙云玲
2021-06-19
-

属猴的每月运势是怎样的?
正月出生猴人性格正月出生猴人,应该珍惜大好时光,你诞生在新年之际,亿万人民对新春的庆贺也就是对你的祝福。受到
 何然
2021-03-22
何然
2021-03-22
-
神箭手平台擅自爬取微信公众号数据被起诉
大数据时代,除直接向用户采集数据之外,另一大数据来源就是使用网络爬虫采集公开信息。从技术中立角度而言,爬虫技术本身并无违法。但爬虫技术如果利用不当,有可能引发诉讼,还有可能被法院认定构成不正当竞争。因
 Bella
2020-03-20
Bella
2020-03-20
-
一个绕过Google谷歌验证码reCAPTCHA的方法
在很多反向代理场景,或是爬虫中我们都会使用脚本程序提取搜索结果而不是使用谷歌镜像。但谷歌搜索(google)的反爬虫及异常流量标准会给我们带来很多麻烦,一旦出现验证码reCAPTCHA,就基本中断了数
 ksbugs
2019-08-16
ksbugs
2019-08-16
赞助链接





